Introduction
Overview
Exercises: 20 minQuestionsObjectives
What is ‘born open’ data?
Why should data be ‘born open’?
Understand how to access resources, ask for help, and give feedback.
Understand what the workshop will contain.
Things You’ll Need To Complete This Tutorial
A Webserver or Website for Online Behavioural Experiements
This workshop focusses on implementing a born open workflow for jsPsych online experiments. Other kinds of online experiments will work well enough, but may take some time for us to help you implement. Having a webserver capable of running PHP scripts will help in following the example section of the workshop.
If you do not have a webserver, install XAMPP using the instructions in the on the homepage.
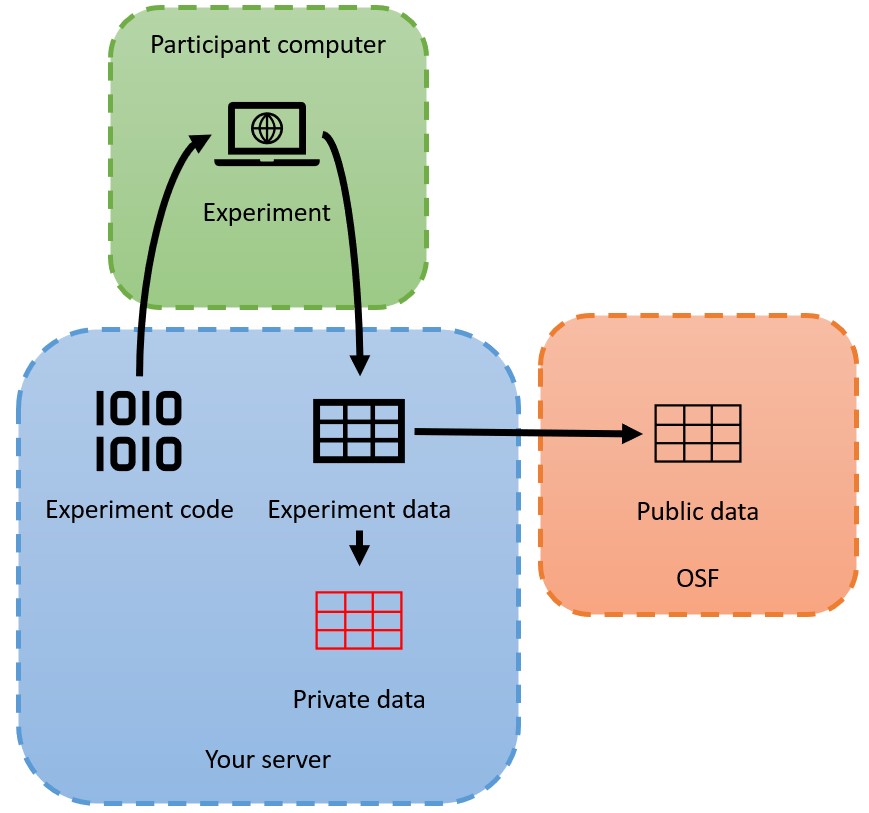
Today we will be implementing a ‘born open’ workflow for our data collection. This will mean that the data we collect will be saved into a publicly-accessible repository at the time we collect it, and when we want to access it we will do so in the same way that other researchers will. We will do our best to ensure that our data is in line with the FAIR sharing principles:
- Findable
- The data will be saved on the OSF, where we can give them a DOI
- Accessible
- We will access our data using the same public OSF interface as everyone else
- Interoperable
- We will save data in .csv format so that it can be loaded by many different programs
- and Reusable
- By giving our data an appropriate license, we will ensure people are clear about how the data can be used
- By supplying a data dictionary which explains the variables, we will make it possible for others to understand our dataset
Discussion why share data?
10 min
- Who has tried to use shared data before?
- What was the experience like?
- Why might we want to share data?
Discussion: concerns about sharing data
10 min
- Why might people worry about having data ‘born open’?
Overview
First, we’ll work through toy example where we adapt the jsPsych quickstart project to save data automatically to an OSF project component. We will cover:
- Cloning or copying the jsPsych quickstart project
- Setting up an OSF project component to house the data
- Setting up an OSF Personal Access Token to authorise saving the data
- Adapting the participant-side file (
index.html) to add a participant id and send data to the server - Creating a server-side file (
save_data.php) to send the data to the OSF - Fetching the data
Later, we’ll have a block of time for you to create a version of one of your current projects which saves to the OSF. We will be here to give you as much help as you need.
Key Points
‘Born open’ means that data are saved to a publicly-accessible location as they are collected.
‘Born open’ data are accessed by the researcher who collects the data in the same way that they are accessed by the public.